
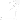
ModelScope Text to Video Synthesis 文本轉影片生成擴散模型是一個強大的自然語言處理工具,它由三個子網絡組成:文本特徵提取、文本特徵到影片潛在空間擴散模型和影片潛在空間到影片視覺空間。該模型的參數總數約為17億。該模型支持英文輸入。擴散模型採用Unet3D結構,通過純高斯噪聲影片的迭代去噪過程實現影片生成功能。



該模型具有廣泛的應用,可以根據任意英文文本描述進行推理和視頻生成。但是,該模型存在一些限制和偏差。例如,該模型是基於公共數據集進行訓練的,因此生成的結果可能存在與訓練數據分布相關的偏差。此外,該模型不能產生清晰的文字,且只支持英文。
使用Elon musk dancing關鍵字生成的4個影片:
使用該模型需要一定的計算資源,例如16GB CPU RAM和16GB GPU RAM。在ModelScope框架下,可以通過調用簡單的Pipeline來使用該模型,其中輸入必須以字典格式進行,合法的鍵值為”text”,內容為短文本。該模型目前僅支持在GPU上進行推理。
為了方便使用該模型,用戶可以參考阿里雲筆記本教程,快速開發這個文本到視頻模型。該模型已經在ModelScope Studio和huggingface上推出,用戶可以直接體驗。
生成一隻豬爬樹然後在菜地吃菜的影片:
當然,在使用該模型時,也需要注意其限制和誤用風險。例如,該模型不能生成與人或事件相關的真實內容,且禁止生成貶低或有害於人類或其環境、文化、宗教等方面的內容。此外,該模型也禁止生成色情、暴力和血腥的內容,以及錯誤和虛假信息。總體而言,該模型是一個非常有用的自然語言處理工具,但需要注意其限制和誤用風險。
Share this content:
相關資訊:
 Streamline Online Meetings with AI-Powered Transcription, Summarization, and Recordings
Streamline Online Meetings with AI-Powered Transcription, Summarization, and Recordings
 摩根大通AI革命:18億美元戰略如何讓50%員工自願使用AI平台
摩根大通AI革命:18億美元戰略如何讓50%員工自願使用AI平台
 摩根大通AI革命:18億美元戰略打造50%員工自願使用的生成式AI平台
摩根大通AI革命:18億美元戰略打造50%員工自願使用的生成式AI平台
 Runway AI: Applied Research for Art, Entertainment, and Human Creativity with AI Tools
Runway AI: Applied Research for Art, Entertainment, and Human Creativity with AI Tools
 Unlocking Creative Potential: Runway AI Tools for Art, Entertainment, and Human Creativity
Unlocking Creative Potential: Runway AI Tools for Art, Entertainment, and Human Creativity
 2025年十大高薪職缺,再掀職場新局!
2025年十大高薪職缺,再掀職場新局!
 雅达利主题酒店2026年动工:电竞沉浸式住宿如何重塑全球游戏旅游产业?
雅达利主题酒店2026年动工:电竞沉浸式住宿如何重塑全球游戏旅游产业?
 Google Messages 2025 更新:多媒體訊息、隱私防護與跨裝置同步如何重塑通訊未來?
Google Messages 2025 更新:多媒體訊息、隱私防護與跨裝置同步如何重塑通訊未來?







