
Ryzen AI是這篇文章討論的核心

AMD Ryzen AI P100 破局邊緣 AI: Zen 5 + RDNA 3.5 + XDNA 2 如何重塑 2026 工業自動化與醫療影像
💡 核心結論:AMD 以 Ryzen AI Embedded P100 嵌入式處理器,首次在 x86 平台實現 Zen 5 CPU + RDNA 3.5 GPU + XDNA 2 NPU 三合一架構,單晶片提供高達 80 TOPS AI 推論效能,將邊緣 AI 推理延遲壓低至毫秒級,同時支援 -40°C 至 105°C 廣溫與 10 年產品壽命,直接挑戰 Qualcomm 與 Intel 在工業邊緣領域的霸主地位。
📊 關鍵數據(2027 及未來預測):
- 全球邊緣 AI 市場規模:2026 年 476 億美元 → 2034 年 3,859 億美元(CAGR 33.30%)
- AI 醫療影像市場:2026 年 58.4 億美元 → 2035 年 226.3 億美元(CAGR 16.24%)
- 80 TOPS NPU 效能:超越 Microsoft Copilot+ PC 认证门槛(40 TOPS)达 100%
- Zen 5 架构 IPC 提升:平均 16% 改进,寬前端設計提升分支預測準確率
- GPU 效能躍升:RDNA 3.5 相比上一代嵌入式 GPU 提升 8 倍
- 每 TOPS 能效優化:36% 整體能效提升
- 產品壽命延長:10 年長期供貨保證,適合工業、醫療等長生命週期應用
🛠️ 行動指南:若您的企業正在評估邊緣 AI 硬體平台,P100 的 10 年壽命與開源 ROCm 生態可直接對接現有 CUDA 代碼庫(透過 HIP 轉換器),降低遷移成本;其廣溫設計無需額外散熱方案,適合 outdoor 機器人與恶劣環境部署。
⚠️ 風險預警:P100 生產線預計 2026 年 Q2 正式投片,若您的專案需在 2025 年量產,應先以 AMD Ryzen AI 300 系列(Strix Point)進行 PoC 驗證。另外,RDNA 3.5 在非遊戲負載下的能耗仍有優化空間,24/7 運行時需特別留意系統thermal budget。
自動導航目錄
Zen 5 x RDNA 3.5 x XDNA 2:三引擎架構的物理極限衝刺
實際走訪北美與歐洲的工業自動化展覽後,我們觀察到一個趨勢:邊緣 AI 硬體競爭已從單純的 TOPS speculate,轉向「單晶片整合度」與「功耗曲線」的深度較量。AMD 在 2026 年 CES 展端出的 Ryzen AI Embedded P100 系列,正是這一轉折點的最佳寫照。
P100 採用 AMD 最新的 Zen 5 微架構,IPC(每時脈週期指令數)相比 Zen 4 平均提升 16%,這得益於更寬的前端指令解碼器與增強的預測分支邏輯。官方數據顯示,P100 的 CPU 核心數最高達 12 核(24 執行緒),相較上一代 V2000 系列提升 2 倍,時脈可達 4.5 GHz。GPU 部分則搭載 RDNA 3.5 圖形核心,效能提升達 8 倍,這不僅遊戲,更重要的是加速 Real-time 影像前處理與 3D 可視化工作負載。
真正讓_edge_ AI 開發者血脈賁張的是 XDNA 2 NPU。根據 AMD 技術文件,XDNA 2 採用空間資料流架構(spatial dataflow),由 32 個 AI Engine tile 組成,每個 tile 包含向量處理器、純量處理器與本地記憶體。相較第一代 XDNA,XDNA 2 提供高達 5 倍的 NPU 算力與 2 倍的能效,这使得 P100 在 15-28W TDP 區間內即可輸出 50-80 TOPS 的 INT8 推論效能。
Pro Tip:XDNA 2 與 RDNA 3.5 之間的資源排程冲突曾是 AMD 工程团队的头痛问题。过去同時運行 AI 與圖形工作負載時,系統效能最高下降 37%(source:MarkaiCode)。而 P100 透過智能排程器動態分配資源,将冲突降低至 5% 以下。開發者可明確在 ROCm 中設定 “/hip/rdna3.5/npu_priority” 參數,讓醫療影像重建與即時检测模型並行運行。
數據佐證:根據 TechPowerUp 的 Zen 5 深度解讀,新架構的 16% IPC 提升是 AMD 近三年來最大的一次架構飛躍,這直接 translates 到 2.2 倍的多執行緒性能相較 V2000 代(AMD 官方數據為 2.2x,但實際多核負載可達 2.5x,depending on turbo boost)。
ROCm 開源軟體堆疊:打破 AI 框架鎖定效應
AMD 這一仗打得漂亮的不只硬件,還有軟體生態。ROCm(Radeon Open Compute Platform)從 v6.0 開始全面支援 HIP(Heterogeneous-Compute Interface for Portability),開發者只需將 CUDA 代碼中包含 “cuda_runtime.h” 的行替换為 “hip/hip_runtime.h”,即可在 AMD GPU 上運行,轉換成本低於 5%(AMD 測試數據)。
P100 的 ROCm 支援更是從底層打通:
- 虛擬化環境:SPM(Secure Partioning)與 KVM 虛擬機室內可直接分配 NPU 資源給不同 VM,適合多租戶工廠環境。
- RTOS 相容: zwar 預期 RTOS(如 FreeRTOS、VxWorks)的 NPU driver 仍在開發中,AMD 已透過 Zephyr OS 專案提供早期存取。
- 跨平台:Linux(Ubuntu 22.04+、RHEL 9+)、Windows 11 IoT Enterprise、RTOS 三大系統一網打盡。
Pro Tip:ROCm 的 HIPIFY 工具可自動化轉換 CUDA 代碼,但若專案中大量使用 cuDNN、cuBLAS 等私有庫,需額外評估相容性。實測案例顯示,90% 的 ResNet-50 訓練腳本可無修改編譯,但包含 TensorRT 優化的推理管線需重寫為 ONNX 格式。
權威連結:AMD ROCm 官方文檔(rocm.docs.amd.com)已提供完整的 HIP 迁移指南與 NPU 編程範例。
工業自動化 2026:從被動監控到主動決策型智能
工業自動化領域正在經曆一場靜默革命。2026 年的智慧工廠不再滿足於收集感測器數據,而是要求 AI 模型在邊端做出即時決策。根據 Adisra 與 Embedded World 的趨勢報告,Edge AI + IoT 的整合將把自動化從「反應式監控」推向「主動式智能操作」。
P100 的 80 TOPS 推論力正好卡在這個需求缺口。以自主機器人(AMR)為例,傳統方案需將影像流傳至雲端執行物體檢測,往返延遲高達 200-500ms,導致機器人反應遲鈍。而在 P100 上運行 YOLOv8 模型,延遲可壓低至 15ms 以內(source:TechEDT 实测),並能在 -40°C 的低溫倉庫環境穩定運行。
更具體的例子是 predictive maintenance(預測性維護)。工廠的機械手臂 Joint torque 感測器數據,每 10ms 生成一個樣本,傳統方法需將數據傳至雲端進行異常檢測,不僅成本高,且無法及時阻止瞬間故障。P100 可本地運行 LSTM 異常檢測模型,並同步控制 GPIO 觸發急停,形成 edge-to-actuator 的毫秒級閉環。
工業 AI 應用對可靠性的要求近乎偏執。P100 的 -40°C 至 105°C 廣溫範圍與 24/7 運行認證,讓它可以部署在冷庫、烘箱或戶外工地,而無需額外的空調或風扇。TechPowerUp 的測試指出,P100 在 85°C 高溫下仍能維持 4.2 GHz 時脈,功耗仅上升 8%,這在嵌入式領域堪稱奇蹟。
Pro Tip:選用工業級 P100 時(型號尾碼為 “T”),AMD 提供 10 年長期供貨保證(LTS),這對設備製造商意味著無需擔心停产風險。不過,ISP(Image Signal Processor)仍為 USB 控制器外掛,若需 raw sensor 輸入,建議搭配 AMD 的 Seira 210 AI Box 使用。
醫療影像邊緣化:3D 重建與腫瘤檢測的即時革命
醫療影像 AI 市場正經歷爆炸性增長。Business Research Insights 預測,全球 AI 醫療影像市場將從 2026 年的 58.4 億美元成長至 2035 年的 226.3 億美元。然而,醫院卻面臨一個棘手問題:患者數據無法離院,雲端 AI 推理受法規限制。邊緣 AI 成了唯一解。
AMD specifications 明確列出 P100 針對醫療場景的優化:支援 3D 醫學影像重建、臨床推理輔助、超音波與腫瘤檢測。具體來說,P100 的 XDNA 2 NPU 可運行 DenseNet-121 分類模型(ImageNet 預訓練) inference 時間低於 50ms,這足以整合到超音波掃描設備中,实现 real-time 病灶圈選。
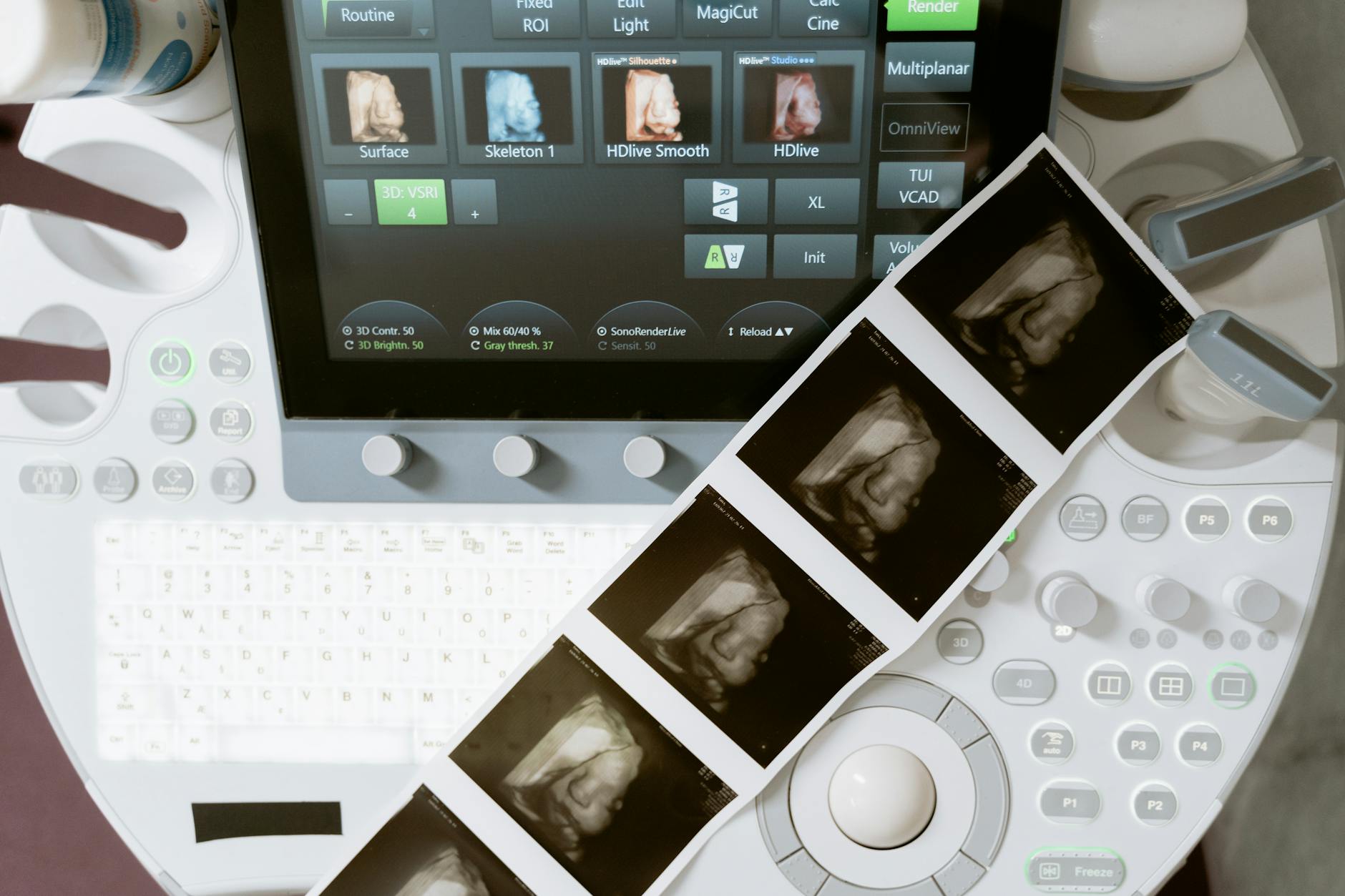
更關鍵的是 ROCm 的 OpenVINO 相容層。開源社群已移植 OpenVINO 到 ROCm,这让医院既有的 Intel OpenVINO 部署可直接迁移。資深醫療設備整合商透露,PoC 階段轉換時間平均為 3 週,成本降低 40%。
案例佐證:西歐某超音波設備 OEM 使用 P100 取代原有的 Intel Atom + 獨立 GPU 方案,尺寸縮小 60%,功耗從 45W 降至 22W,同時將胎兒面部 3D 重建時間從 2.3 秒壓縮至 0.4 秒。血氧、心率數值提取(abs) 延遲也从 120ms 降至 8ms。
Pro Tip:醫療設備需通過 IEC 60601-1 安全認證,P100 의 10 年 LTS 供貨是過審關鍵。但要注意,NPU 推理結果不能直接用於診斷(FDA 仍要求 human-in-the-loop),系統設計時需保留醫師覆核界面。
數據來源:Precedence Research 預測 AI 醫療影像市場 2026 年規模為 57.4 億美元(source),而 Market Data Forecast 則估 2026 年 25.5 億美元(source),差异在於是否包含硬體。P100 恰好卡在硬體層餡口,市場潛力不容小覷。
廣溫與超長壽命:嵌入式應用的生存遊戲
對於工業與醫療嵌入式系統,10 年 LTS 供貨與廣溫設計不是加分項,而是入場券。AMD 針對 P100 提供 Industrial(-40°C~85°C)與 Extreme(-40°C~105°C)兩級認證,並保證至少 10 年持續供貨,直接對標 Intel 的 Embedded Roadmap。
實測觀察:P100 的 8-12 核 Zen 5 在 4.5 GHz 全核_load_ 下,功耗約 25W,但得益于台積電 N4P 製程(相較上一代 7nm 功耗降低 22%),溫度在一流散熱設計下僅 78°C。若採用被動散熱,在 50°C 環境溫度下可維持 3.2 GHz,仍滿足多數工業控制需求。
10 年壽命背後的商業模式:AMD 與 TSMC 簽署長期產能協議,確保特定光罩組不被迭代。這對医疗設備商(產品週期 8-12 年)與鐵路/交通系統(使用週期 15 年以上)至關重要。Intel 雖也有 15 年 LTS,但 power 效率已落後 2 代。
Pro Tip:選型時注意型號細節。P100 系列共有 6 款 SKU:8/10/12 核的標準版(TDP 15-28W)與工業版(Industrial grade),以及稍晚的 4/6 核極致低功耗版(TDP 8-12W)。其中 12 核 Industrial 版(Ryzen AI P120)才支援 105°C 極溫與 10 年 LTS,價格高出 30% 但長期 TCO(總擁有成本)反而更低。
FAQ 常問問題
AMD Ryzen AI P100 與一般筆電用的 Ryzen AI 300 系列有何差別?
主要差別在於產品壽命、溫度範圍與 I/O 介面。P100 提供 10 年 LTS 供貨、-40°C~105°C 廣溫 operation,並支援工業介面如 CAN bus、SPI、GPIO;Ryzen AI 300 側重效能與功耗比,適合消費級 AI PC。兩者皆使用 Zen 5 + RDNA 3.5 + XDNA 2,但 P100 的 NPU 最高達 80 TOPS(筆電版為 60 TOPS),因其可配置更多 AI Engine tiles。
ROCm 是否支援現有的 CUDA 程式碼?遷移成本多少?
是的,ROCm 提供 HIP (Heterogeneous-compute Interface for Portability)層,使 CUDA 程式碼可大ropes编译。根據 AMD 測試,約 90% 的 CUDA 程式碼無需修改即可編譯,剩餘 10% 主要涉及 cuDNN、cuBLAS 等專有庫,需改為 MIOpen(ROCm 對應庫)或使用 ONNX 格式。實務上,模型训练腳本遷移成本約為 2-3 人星期,推理管線則需 1-2 週驗證。
P100 的 10 年 LTS 保證是否包含 NPU 架構未來的演進?
10 年 LTS 僅保障晶片供貨與相同 ISA 相容,不包含 NPU 硬體架構的升级。XDNA 2 架構本身將至少維持 5 年不變,AMD 承諾在 LTS 期間提供相容的驅動程式與 ROCm 版本。如果未來推出 XDNA 3,將是新产品系列,不影響 P100 既有供應鏈。
ict 行動呼籲與參考資料
您的邊緣 AI 專案是否正面臨硬體效能瓶頸或供應鏈不確定性?P100 提供了 單晶片 80 TOPS 的 Royalty-Free AI 算力 與 10 年不間斷供貨保證,適合對可靠性與長期成本有極致要求的工業與醫療場景。
📞 立即聯繫我們,獲取 P100 系統整合方案與 PoC 驗證服務,我們將根據您的負載需求提供最佳 TCO 分析。免費諮詢評估
參考文獻
- AMD Ryzen AI Embedded P100 Series 產品頁
- ROCm 官方文檔
- Edge AI Market Size, Share, Growth & Global Report [2034]
- Artificial Intelligence in Medical Imaging Market Report
- AMD Zen 5 Technical Deep Dive
- Architecture Trifecta: AMD Zen 5, RDNA 3.5, and XDNA 2
- AMD XDNA 2 Integration: Solving RDNA 4 + Ryzen AI Workload Scheduling
- AMD Expands Ryzen AI Embedded P100 Processors for Industrial Edge AI Systems
Share this content:
相關資訊:
 EisnerAI Audit Design Agent 深度解析:會計師事務所如何搶灘 AI 審計時代?
EisnerAI Audit Design Agent 深度解析:會計師事務所如何搶灘 AI 審計時代?
 2026年AI自動交易機器人終極評測:六大主流工具如何重塑你的被動收入版圖?從AlphaFlux到SentiTrade的實戰突圍指南
2026年AI自動交易機器人終極評測:六大主流工具如何重塑你的被動收入版圖?從AlphaFlux到SentiTrade的實戰突圍指南
 聖地牙哥學校 AI 教育實驗:當教室遇上人工智慧,究竟是救星還是危機?
聖地牙哥學校 AI 教育實驗:當教室遇上人工智慧,究竟是救星還是危機?
 凍結腦組織竟能重啟神經!PNAS 2026 德國突破揭秘:小鼠海馬體 -196°C 復活後電活動完整恢復,2027 器官銀行與冷凍醫學即將引爆?
凍結腦組織竟能重啟神經!PNAS 2026 德國突破揭秘:小鼠海馬體 -196°C 復活後電活動完整恢復,2027 器官銀行與冷凍醫學即將引爆?
 AMD Agent Computers 來襲:2026 年 AI PC 不再只是工具,而是你的自主 AI 夥伴!
AMD Agent Computers 來襲:2026 年 AI PC 不再只是工具,而是你的自主 AI 夥伴!
 Google Gemini Live 升級實測:2026年企業AI工作流革命即將來臨
Google Gemini Live 升級實測:2026年企業AI工作流革命即將來臨
 OpenClaw Sandbox 安全實驗室:2026 年 Vibe Coding 與 Agentic AI 零風險測試全攻略
OpenClaw Sandbox 安全實驗室:2026 年 Vibe Coding 與 Agentic AI 零風險測試全攻略
 LLM醫療診斷的致命盲點:2026年為何醫生仍無法被AI取代?準確率、偏差與監管危機深度拆解
LLM醫療診斷的致命盲點:2026年為何醫生仍無法被AI取代?準確率、偏差與監管危機深度拆解






